
Raspberry Pi Speech Recognition Introduction
This tutorial demonstrate how to use voice recognition on the Raspberry Pi. By the end of this demonstration, we should have a working application that understand and answers your oral question.

Buy the Raspberry Pi from: Banggood | Amazon
This is going to be a simple and easy project because we have a few free API available for all the goals we want to achieve. It basically converts our spoken question into to text, process the query and return the answer, and finally turn the answer from text to speech. I will divide this demonstration into four parts:
- speech to text
- query processing
- text to speech
- Putting Them Together
Result Example:
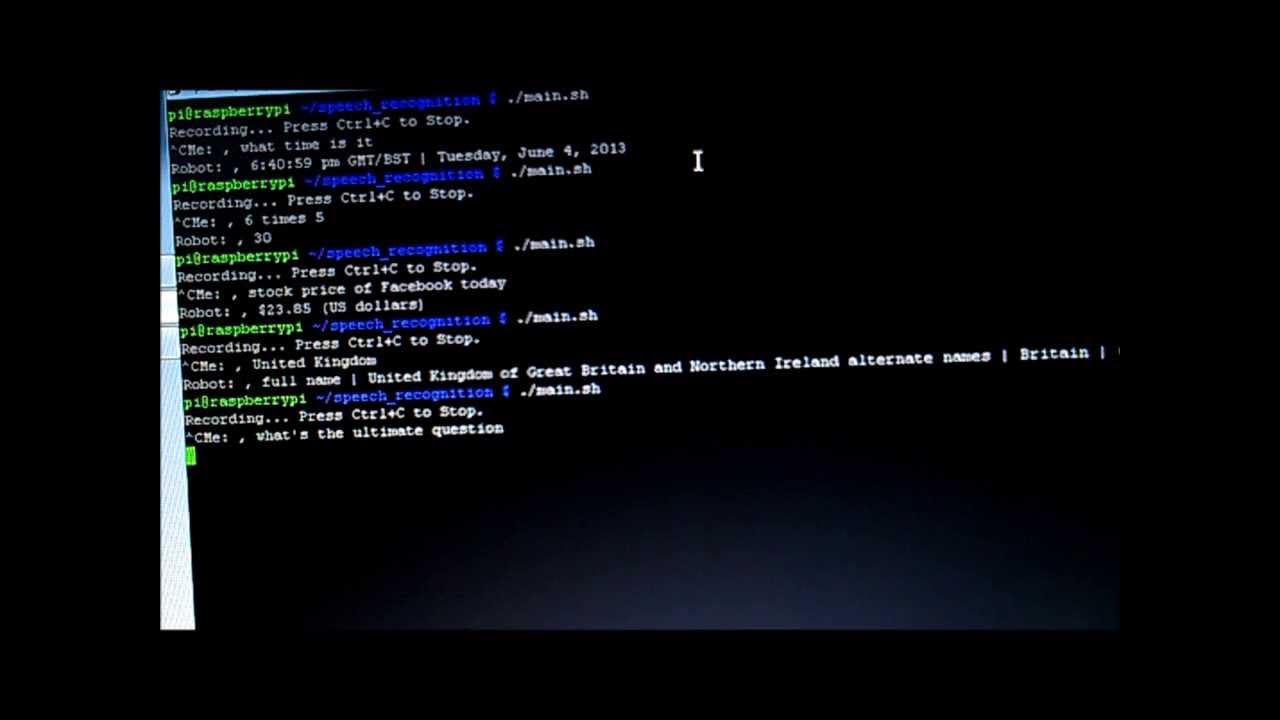
Raspberry Pi Voice Recognition For Home Automation
This has been a very popular topic since Raspberry Pi came out. With the help of this tutorial, it should be quite easily achieved. I actually having an idea of combining the Speech recognition ability on the Raspberry Pi with the powerful digital/analog i/o hardware, to build a useful voice control system, which could also be adopted in Robotics and Home Automation. This will be in the next couple of blog posts.
Hardware and Preparation

You can use an USB Microphone, but I don’t have one so I am using the built-in Mic on my webcam. It worked straight away without any driver installation or configuration.

Of course, the Raspberry Pi as well.

You will also need to have internet connection on your Raspberry Pi.
Speech To Text
Speech recognition can be achieved in many ways on Linux (so on the Raspberry Pi), but personally I think the easiest way is to use Google voice recognition API. I have to say, the accuracy is very good, given I have a strong accent as well. To ensure recording is setup, you first need to make sure ffmpeg is installed:
sudo apt-get install ffmpeg
To use the Google’s voice recognition API, I use the following bash script. You can simply copy this and save it as ‘speech2text.sh‘
[sourcecode language=”bash”]
#!/bin/bash
echo “Recording… Press Ctrl+C to Stop.”
arecord -D “plughw:1,0” -q -f cd -t wav | ffmpeg -loglevel panic -y -i – -ar 16000 -acodec flac file.flac > /dev/null 2>&1
echo “Processing…”
wget -q -U “Mozilla/5.0” –post-file file.flac –header “Content-Type: audio/x-flac; rate=16000” -O – “http://www.google.com/speech-api/v1/recognize?lang=en-us&client=chromium” | cut -d” -f12 >stt.txt
echo -n “You Said: ”
cat stt.txt
rm file.flac > /dev/null 2>&1
[/sourcecode]
What it does is, it starts recording and save the audio in a flac file. You can stop the recording by pressing CTRL+C. The audio file is then sent to Google for conversion and text will be returned and saved in a file called “stt.txt”. And the audio file will be deleted.
And to make it executable.
chmod +x speech2text.sh
To run it
./speech2text.sh
The screen shot shows you some tests I did.

Query Processing
Processing the query is just like “Google-ing” a question, but what we want is when we ask a question, only one answer is returned. Wolfram Alpha seems to be a good choice here.
There is a Python interface library for it, which makes our life much easier, but you need to install it first.
Table of Contents
Installing Wolframalpha Python Library
Download package from https://pypi.python.org/pypi/wolframalpha, unzip it somewhere. And then you need to install setuptool and build the setup.
apt-get install python-setuptools easy_install pip sudo python setup.py build
And finally run the setup.
sudo python setup.py
Getting the APP_ID
To get a unique Wolfram Alpha AppID, signup here for a Wolfram Alpha Application ID.
You should now be signed in to the Wolfram Alpha Developer Portal and, on the My Apps tab, click the “Get an AppID” button and fill out the “Get a New AppID” form. Use any Application name and description you like. Click the “Get AppID” button.
Wolfram Alpha Python Interface
Save this Pyhon script as “queryprocess.py”.
[sourcecode language=”python”]
#!/usr/bin/python
import wolframalpha
import sys
# Get a free API key here http://products.wolframalpha.com/api/
# This is a fake ID, go and get your own, instructions on my blog.
app_id=’HYO4TL-A9QOUALOPX’
client = wolframalpha.Client(app_id)
query = ‘ ‘.join(sys.argv[1:])
res = client.query(query)
if len(res.pods) > 0:
texts = “”
pod = res.pods[1]
if pod.text:
texts = pod.text
else:
texts = “I have no answer for that”
# to skip ascii character in case of error
texts = texts.encode(‘ascii’, ‘ignore’)
print texts
else:
print “Sorry, I am not sure.”
[/sourcecode]
You can test it like this shown in the screen shot below.

Text To Speech
From the processed query, we are returned with an answer in text format. What we need to do now is turning the text to audio speech. There are a few options available like Cepstral or Festival, but I chose Google’s speech service due to its excellent quality. Here is a good introductions of these software mentioned.
First of all, to play audio we need to install mplayer:
sudo apt-get install mplayer
We have this simple bash script. It downloads the MP3 file via the URL and plays it. Copy and call it “text2speech.sh“:
[sourcecode language=”bash”]
#!/bin/bash
say() { local IFS=+;/usr/bin/mplayer -ao alsa -really-quiet -noconsolecontrols “http://translate.google.com/translate_tts?tl=en&q=$*”; }
say $*
[/sourcecode]
And to make it executable.
chmod +x text2speech.sh
To test it, you can try
./text2speech.sh "My name is Oscar and I am testing the audio."
Google Text To Speech Text Length Limitation
Although it’s very kind of Google sharing this great service, there is a limit on the length of the message. I think it’s around 100 characters.
To work around this, here is an upgraded bash script that breaks up the text into multiple parts so each part is no longer than 100 characters, and each parts can be played successfully. I modified the original script is from here to fit into our application.
[sourcecode language=”bash”]
#!/bin/bash
INPUT=$*
STRINGNUM=0
ary=($INPUT)
for key in “${!ary[@]}”
do
SHORTTMP[$STRINGNUM]=”${SHORTTMP[$STRINGNUM]} ${ary[$key]}”
LENGTH=$(echo ${#SHORTTMP[$STRINGNUM]})
if [[ “$LENGTH” -lt “100” ]]; then
SHORT[$STRINGNUM]=${SHORTTMP[$STRINGNUM]}
else
STRINGNUM=$(($STRINGNUM+1))
SHORTTMP[$STRINGNUM]=”${ary[$key]}”
SHORT[$STRINGNUM]=”${ary[$key]}”
fi
done
for key in “${!SHORT[@]}”
do
say() { local IFS=+;/usr/bin/mplayer -ao alsa -really-quiet -noconsolecontrols “http://translate.google.com/translate_tts?tl=en&q=${SHORT[$key]}”; }
say $*
done
[/sourcecode]
Putting It Together
For all of these scripts to work together, we have to call them in a another script. I call this “main.sh“.
[sourcecode language=”bash”]
#!/bin/bash
echo “Recording… Press Ctrl+C to Stop.”
./speech2text.sh
QUESTION=$(cat stt.txt)
echo “Me: “, $QUESTION
ANSWER=$(python queryprocess.py $QUESTION)
echo “Robot: “, $ANSWER
./text2speech.sh $ANSWER
[/sourcecode]
I have also updated and removed all the ‘echo’ commands from “speech2text.sh”
[sourcecode language=”bash”]
#!/bin/bash
arecord -D “plughw:1,0” -q -f cd -t wav | ffmpeg -loglevel panic -y -i – -ar 16000 -acodec flac file.flac > /dev/null 2>&1
wget -q -U “Mozilla/5.0” –post-file file.flac –header “Content-Type: audio/x-flac; rate=16000” -O – “http://www.google.com/speech-api/v1/recognize?lang=en-us&client=chromium” | cut -d” -f12 >stt.txt
rm file.flac > /dev/null 2>&1
[/sourcecode]
Finally, make “main.sh” executable, run it and have silly conversation with your computer :-)
chmod +x text2speech.sh ./main.sh
The End
That’s the end of Raspberry Pi Voice Recognition tutorial, but it’s just the beginning of fun! You can now modify this project and turn it into something really cool, let me know what you can come up with. In the next project, I will exploit the speech to text feature, to make a voice control system to control an Arduino board, and even better, a robot.
Have fun.
Note: Errors You May Get
mplayer: could not connect to socket
If you gets this error, all you need to do to is to disable LIRC support by doing the following:
sudo nano /etc/mplayer/mplayer.conf
And put in the line:
nolirc=yes
And that should sort it out.
UnicodeEncodeError: ‘ascii’ codec can’t encode character u’xxx in position x: ordinal not in range(128)
I tend to just ignore those character for now, if you know a good way to convert them please let me know. In the ‘queryprocess.py’ script, replace the ‘print’ command just above ‘else’ with these lines (which I have done).
texts = texts.encode('ascii', 'ignore')
print texts
Some More errors people have been having
Problems
When I tried sudo apt-get install ffmpeg I got this error:
- Unable to locate package ffmeg
When I tried apt-get install python-setuptools easy_install pip I got this error:
- E: Unable to locate package easy_install
- E: Unable to locate package pip
Solution
Make sure your Pi is connected to the internet when you run these commands. Type the ifconfig command to make sure that your ethernet or wifi adapter has an IP address.
When using APT, one should first always use:
- sudo apt-get update
- sudo apt-get upgrade
To re-synchronise the package / sources and ensure that Raspbian is up-to-date: http://linux.die.net/man/8/apt-get
Easy Install is a python module (easy_install) bundled with setuptools and pip should be python-pip, therefore:
- sudo apt-get update
- sudo apt-get upgrade
- apt-get install ffmpeg
- apt-get install python-setuptools
- apt-get install python-pip
- apt-get install mplayer
—————————————————–
Problems
When I attempt to run ./queryprocess.py and type in “what time is it?” I got this error:
- bash: ./queryprocess.py: Permission denied
solution
Type this command to make your script executable:
chmod +x ./queryprocess.py
—————————————————–
156 comments
Has anyone shopped at Bluegrass Vape – Independence Vapor Store in 8528 N 2nd St?
but when use google speech recognition, i pay for the service?
Hi Oscar, I would like to ask that is it possible to use the speech to text function offline and link it to a database? Since my project need mobility and might not have ethernet port. Thank you.
May i know how to sole this issue? thanks
pi@raspberrypi:~ $ chmod +x speech2text.sh
chmod: changing permissions of ‘speech2text.sh’: Operation not permitted
Hello! Have you tried to be root when making this action?
Sudo chmod*
use sudo before chmod
Prefix with sudo
when running speect2text.sh I get this error………ALSA lib pcm.c:2239:(snd_pcm_open_noupdate) Unknown PCM “plughw:1,0”
arecord: main:722: audio open error: No such file or directory
Having problem connecting to google speech api. As a test I ran the following which just hung. Any suggestions?
Note:I’ve substituted api key in the following for security purposes. I know key is correct since i just received it.
wget -U “Mozilla/5.0” –post-file /home/pi/good-morning-google.flac –header “Content-Type: audio/x-flac; rate=44100” -O – “https://google.com/speech-api/v2/recognize?lang=en-us?key=mykey” > stt.txt
–2016-05-22 11:26:28– https://www.google.com/speech-api/v2/recognize?lang=en-us?key=mykey
Resolving http://www.google.com (www.google.com)… 216.58.219.68, 2607:f8b0:4008:804::2004
Connecting to http://www.google.com (www.google.com)|216.58.219.68|:443… connected.
Hey am newbie am trying to develop similar app with raspberry pie 2 model b, thanks for the great tutorial but i got struck with the google speech api i couldnt able to see the speech api listed in the developer console (https://console.developers.google.com/apis/library) could any one please guide me to get a key for speech processing. thanks in advance
Great topic and well written. Do you have any more resources about this that you reccommend?
Hi Oscar.
Right off the bat I get “Package ffmpeg is not available, but is referred to by another package…. no installation candidate”.
Also, I don’t have a USB microphone yet, so will it work through the computer microphone? Please reply soon.
Thanks
“apt-get install libav-tools” will get you ffmpeg
source: raspberrypi.org/forums/viewtopic.php?f=38&t=123952
I had your deployment working in Raspberry Pi Model B, but the text2speech.sh function is not outputting any sound in the Model B+ Version, although the Answer is displayed properly in the Terminal. Would you understand why? Thank you.
Would it work on Orange PI?
Hi,
I want to incorporate this project into my home automation project.
However, i don’t want to be recording and sending to google all the time.
I’d like to have something that works like siri.
Something that is constantly listening for 1 keyword, when it hears that keyword, then it should start sending to google.
Anyone knows about such a program?
@nightwalker did you ever figure it out? I am looking for something very similar.
https://github.com/hey-athena/hey-athena-client
You can use pocketsphinx / speech_recognition in python like they did. I am making my own project based on that.
With those libraries you can get the “keyword” trigger with pocketsphinx and the speech recognition with pocketsphinx (offline, not very precise), Google, Bing, etc…).
You’ll need an API key for Google and Bing. Good luck.
My tests. Check the stt.py file
soc.ninja/gitweb/?p=testing.git;a=tree;f=BOT;h=e71c98f25d383ccf67d498bb1daa2d987aed3598;hb=HEAD
Does anyone know how to get the Google API of the first script to work?
Thanks in advance!
Google speech api V1 has expired.
You need to use Google speech api V2 which require you to signed up for it and get a key.
Change the speech2text.sh with:
wget -O – -o /dev/null –post-file out.flac –header=”Content-Type: audio/x-flac; rate=16000″ “http://www.google.com/speech-api/v2/recognize?lang=en-us&key=YOUR_KEY&output=json” > out.json
Hi Oscar,
We tried using the V2 after generating our own key, but it’s throwing an error msg “No such file or directory”. Here’s what we used – wget -O – -o /dev/null –post-file out.flac –header=”Content-Type: audio/x-flac; rate=16000″ “http://www.google.com/speech-api/v2/recognize?lang=en-us&key=YOUR_KEY&output=json” > out.json
We replaced ‘YOUR_KEY’ with our key. Can you please check and advise?
I have one bug :(
Processing…
wget: –header: Invalid header `Content-Type:naudio/x-flac; rate=16000′.
you Said: pi@raspberrypi – $
help me plz :(
use this:
wget -O – -o /dev/null –post-file out.flac –header=”Content-Type: audio/x-flac; rate=16000″ “http://www.google.com/speech-api/v2/recognize?lang=en-us&key=YOUR_KEY&output=json” > out.json
wget -O – -o /dev/null –post-file out.flac –header=”Content-Type: audio/x-flac; rate=16000″ “http://www.google.com/speech-api/v2/recognize?lang=en-us&key=YOUR_KEY&output=json” > out.json
hi Oscar,
i have webcam c270. RPi os raspbian.
Problem: ./speech2text.sh:line 5 $’arecord302240-D’ :command not found
i can record : #arecord xyz.wav
i can play: #aplay -D hw:1,0 xyz.wav
Thanks in advance!!!!
It’s the google speech recognition api. It changed somehow, so you’ll have to figure out how to change the wget client for it to work.
Speech2text code doesn’t work any more now. it was working on my RPI.
Do you guys this code is working now?
text2speech code is working now.
Do you have any idea about this? or someone has same issue as me.
wget -O – -o /dev/null –post-file out.flac –header=”Content-Type: audio/x-flac; rate=16000″ “http://www.google.com/speech-api/v2/recognize?lang=en-us&key=YOUR_KEY&output=json” > out.json
Banana PI, New generation development Board made in China, an run Android 4.4, Ubuntu, Debian, Rasberry Pi Image, as well as the Cubieboard Image
What’s Banana Pi?
It’s an open-source single-board computer. It can run Android 4.4, Ubuntu, Debian, Raspberry Pi Image,more powerful than raspberry pi
What can I do with Banana Pi?
Build…
A computer
A wireless server
Games
Music and sounds
HD video
A speaker
Android
Scratch
Pretty much anything else, because Banana Pi is open source
Who’s it for?
Banana Pi is for anyone who wants to start creating with technology – not just consuming it. It’s a simple, fun, useful tool that you can use to start taking control of the world around you.
Hi Oscar,
I have installed raspberry pi on a vm to work faster. I am using MAC.
So when i run your script i get the following
rpi@RaspberryPi:~/bozims$ sudo ./speech2text.sh
Recording… Press Ctrl+C to Stop.
Processing..
Meaning that it doesn’t wait for the recording. I tried to run this command partially
arecord -D “plughw:0,0” -q -f cd -t wav
and this is working fine and i can see recording there in binary format but when i run the part after |
rpi@RaspberryPi:~/bozims$ ffmpeg -loglevel panic -y -i – -ar 16000 -acfile.flac > /dev/null 2>&1
nothing happens
rpi@RaspberryPi:~/bozims$ ls
speech2text.sh stt.txt
i can’t find any flac file here as well.
Any idea what can be the problem ? I am not getting any error which is very confusing.
Thanks for this awesome tutorial. It helped me a lot.
hi Oscar
I use the same code yo run it
but pi got no respond
Processing…..
You said:
pi@raspberrypi~$
I also try
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install ffmpeg
pi is all install….= =
so I really don’t know what ythe problem with it = =
Hello,
Thanks for this how to, it’s great!
I’m getting issues, when I run the main.sh, only one question is allowed it seems unstable.
After that the script output :
Me: ,
Answer: Sorry I’m not sure
I have the same issue when I run the speech2text script.
Any ideas?
I’ve installed wolfram-engine on the rasberry pi (alpha seems to be outdated)
Regards,
Dav
i have a ms lifecam vx-6000 v1.0 and the recording is too bad. Probably that’s why google can’t make any speech to text conversion.
Here is a sample file https://www.dropbox.com/s/5uxh0w5f5ivhqok/file.flac.
Is there any solution on this?
Running “arecord -D plughw:1 –duration=10 -f cd -vv file.flac” i get the above,
Recording WAVE ‘file.flac’ : Signed 16 bit Little Endian, Rate 44100 Hz, Stereo
Plug PCM: Route conversion PCM (sformat=S16_LE)
Transformation table:
0 <- 0
1 <- 0
Its setup is:
stream : CAPTURE
access : RW_INTERLEAVED
format : S16_LE
subformat : STD
channels : 2
rate : 44100
exact rate : 44100 (44100/1)
msbits : 16
buffer_size : 22050
period_size : 5512
period_time : 125000
tstamp_mode : NONE
period_step : 1
avail_min : 5512
period_event : 0
start_threshold : 1
stop_threshold : 22050
silence_threshold: 0
silence_size : 0
boundary : 1445068800
Slave: Rate conversion PCM (16000, sformat=S16_LE)
Converter: linear-interpolation
Protocol version: 10002
Its setup is:
stream : CAPTURE
access : MMAP_INTERLEAVED
format : S16_LE
subformat : STD
channels : 1
rate : 44100
exact rate : 44100 (44100/1)
msbits : 16
buffer_size : 22050
period_size : 5512
period_time : 125000
tstamp_mode : NONE
period_step : 1
avail_min : 5512
period_event : 0
start_threshold : 1
stop_threshold : 22050
silence_threshold: 0
silence_size : 0
boundary : 1445068800
Slave: Hardware PCM card 1 'USB20 Camera' device 0 subdevice 0
Its setup is:
stream : CAPTURE
access : MMAP_INTERLEAVED
format : S16_LE
subformat : STD
channels : 1
rate : 16000
exact rate : 16000 (16000/1)
msbits : 16
buffer_size : 8000
period_size : 2000
period_time : 125000
tstamp_mode : NONE
period_step : 1
avail_min : 2000
period_event : 0
start_threshold : 0
stop_threshold : 8000
silence_threshold: 0
silence_size : 0
boundary : 2097152000
appl_ptr : 0
hw_ptr : 0
##################################################+| 99%overrun!!! (at least 32.046 ms long)
Status:
state : XRUN
trigger_time: 2880.581903178
tstamp : 2880.902331092
delay : 2
avail : 22048
avail_max : 22089
##################################################+| 99%
Hey there !
Im having just a hard time when the text is been read.
Because of the break every 100 characters, the system pauses for 2 seconds and comeback to start reading the next line. But this little pause makes you loose the understanding of the computer is saying… I don’t know if that makes sense, but is there any trick to remove the little pause in between the 100 characters ?!
Thank you very much !
Thiago
I have been experimenting with this over the past few days. As an early I’ve created a simple breadboard circuit that invokes the script via a button press – creates a ten second recording period (I figure this is long enough for any input), then submits. The microphone is taken care of by a Creative Play USB sound card, which will be stripped down and soldered directly to the Pi when I make the appropriate enclosure. The text input / output is displayed on a 20×4 LCD display, and the mp3 is played via a small speaker on the breadboard.
The main problem is speed. It isn’t quite as seem less as it should be. The Pi is over clocked to 900mhz and I have reduced GPU RAM to a minimum, and I am using a class 10 SD card. I’m going to experiment with streamlining Raspbian as much as possible.
yes you are right, RPi is a bit slow for that kind of stuff (voice recognition / object recognition etc…) hope they can make the board more powerful in the future.
I was thinking of something similar to this in a smallish custom enclosure, inbuilt mic and a small speaker, 20×4 LCD to indicate listening and write out the response and a button to activate the script – it could be useful for quite a few things as well as the Siri like functions, especially when given the ability to talk to other networked devices.
sounds like a good project :-D
Hi I have been working on voice recognization project.
I have installed mplayer and used the following script for playing the inputted text.
it didnt work.
then I installed omxplayer and using the following script to play the inputted text, then it worked
——————————————————————————————————————————————
#!/bin/bash
say() { local IFS=+;/usr/bin/omxplayer “http://translate.google.com/translate_tts?tl=en&q=$*”; }
say $*
——————————————————————————————————————————————-
Now the problem with the omxplayer hangs sometimes and holds the shell and not able to come out.
do i need to do some changes in the above script ..
Please help me ….Your help will be appreciated.
This API ” http://www.google.com/speech-api/v1/recognize?lang=en-us&client=chromium” Doesn’t work please give another one or tell me an alternative Idea.
(400. That’s an error.
Your client has issued a malformed or illegal request. Content-Type should be of the form: audio/xxx; rate=yyy That’s all we know.)
Fine way of describing, and fastidious piece of writing to get data about my
presentation subject, which i am going to convey in institution of higher education.
Hi Oscar,
you are just amazing! After 4 hours it finally works! But one big problem:
1) After running the main.sh script, I have to wait 7 seconds to ask a question otherwise it will not record
2) After typing CRL C the process takes around 13 seconds to give me an audio answer back
3) In total the system needs 20 seconds to answer one question
Can you help me to solve that issue? Hope to hear from you soon Oscar!
Raphael
I did struggled with the speed as well. Here is what I found.
Point 1) it could possibly related to system speed, for example the class of your SD card could affect how fast your system runs. Try to kill any other process and application that you are not using. My was taking 3 to 5 seconds to start recording after pressing ctrl + C.
I know poin 2) is definately related to internet speed. It was much quicker for me when using LAN than Wifi. Usually it takes me 3 to 4 seconds to get an answer.
So the total time was 6 to 9 seconds, which is reasonable. Don’t expect you will get anything instantaneous, don’t forget your are running this on the RPi which is not a powerful device at all (your smart phone is probably a few times more powerful than that!)
test
what do you want to test? :)
Hi
I’m trying to do this using the logitech c270 and I cannot get the speech entry element to work whenever I try the light on the webcam does not come on and the screen displays ‘Invalid byte or field list’
Any idea on how to fix this would be gratefully received
sorry, double posted same question, apologies
Hi Oscar, nice project and really good of you to share your skills with others, much appreciated.
really like this project but curious if it can be taken 1 step further, and how difficult it may be for a beginner. what I would like to configure is a “print” command, that displays the answer on a small tft monitor attached to pi, for instance I would like to say
“print map of usa”
and the result is stars+stripes printed to the tft
any pointers or tips most welcome mate
Hello, what model is your Logitech camera?. It seems the C270 but the manufacturer says that it is not compatible with Linux … ? Thank you very much. Very good tutorial. Gustavo
i think it is the C270 (i don’t have the package anymore and it looks the same on their website), and it’s working fine for me.
In my country there are C270 I am going to buy one and try. I will comment the results of the test. Thank you very much.
Hey Oscar, really cool project you got here and awesome of you to share it with the world , top bloke.
one thing I would really like to do is have it display images on an attached small tft display, whilst still keeping its current audio features, for instance command “print usa flag” would display the stars+stripes on the tft, presume a seperate script will be needed for the “print” command ? any pointers for a noob how I could accomplish this and is it a noob friendly job ?
many thanks and best wishes from UK
firstly, create a script that displays different images (flags), and you just need to feed that script to your speech recognition system, when command received.
Hi, Oscar,
This is a ridiculously cool project! Every step worked for me, but then trying to put it all together, it just says I don’t know. Even going back and running speech2text.sh again just gives a blank.
Ambitious idea, anyway!
Thanks,
Peter
Traceback (most recent call last):
File “C:Userssamue_000Desktopqueryprocessing.py”, line 13, in
res = client.query(query)
File “C:Python33libsite-packageswolframalpha-1.0.2-py3.3.eggwolframalpha__init__.py”, line 68, in query
assert resp.headers.gettype() == ‘text/xml’
AttributeError: ‘HTTPMessage’ object has no attribute ‘gettype’
is what I get when running it. I guessed it could be a problem (I am using Python 3.3) so incise this was written in Python 2.7. I am about to try that, however, do you know of a solution?
It worked on 2.7.
Hi, i just setup my own raspberry pi and am still pretty new to this. I am wondering if it is possible that i am able to tell the raspberry pi to play a local radio station like how you tell the raspberry the date or what is beatles? Is there any guide to it as i am still pretty new thanks!
i believe it’s possible although i haven’t done this. There are two parts, first you will need to google how to activate and play the radio station using command line script, then use the voice recognition to try to catch a keyword such as “play radio”, and run that script.
i would like to try and do your example above. Hopefully i get it working and when it’s done i would take a look at the radio station.
i started on this thing and came upon an error. After typing chmod +x speech2text.sh ( automatically goes to the next line ) and type in ./speech2text.sh and get a syntax error near unexpected token ‘(
Any idea how i can solve it?
It’s possible to change the response language ?? i wont to set the response and the question in another language…
sorry form my English
it really depends on google, if you could find a speech recognition API that support your language, then yes.
hey, nice tutorial!
I’m using avconv instead of ffmpeg to make mt flac file, as ffmpeg was acting erratically and I got tired of fussing with it.
To save internet lag time, I’m using flite to speak the response I get from Wolfram Alpha. Voice is less clear, of course, but it does sound more robot-ish.
So thanks for the great writeup. Didn’t even think of trying this before reading it.
The upside is that my robot project is now conversant. The downside is that I now need an additional RPi because doing this while doing face tracking with openCV is just too much for one board to handle.
If you have any interest in seeing the robot into which this has been integrated, it’s the Model III in the Google+ community ‘World Robotics Project’
I thought my mic was working but considering it holds it’s own sound card, that is probably where I was getting the feedback from so the Pi wasn’t receiving anything?
I have set up a bluetooth headset however, and that also doesn’t work, same problem…
Any ideas on what might be the problem or what might be a solution?
I am running Rasbian, if that helps…
I keep getting this error:
pi@raspberrypi ~ $ ./speech2text.sh
Recording… Press Ctrl+C to Stop.
^CProcessing…
cut: invalid byte or field list
Try `cut –help’ for more information.
Any idea what I have to do to fix it?
sounds like your mic is not recording. have you tried Part one ? and is your mic working in Raspberry Pi ?
Yes I am pretty sure it is working I was using a Turtle beach headset and I was getting feedback but I also suppose that the Turtle beach has a sound card and that’s how I was receiving feedback, perhaps it still is my microphone? Is there anything else it could possibly be?
I think you have to pay to use the google api now. That’s why.
hello there and thank you for your info – I’ve certainly picked
up something new from right here. I did however expertise several technical points using this website, since I experienced to reload the site
lots of times previous to I could get it to load properly.
whoah this weblog is great i love studying your posts.
Keep up the great work! Yoou understand,
many people are hunting around ffor this info, you can hellp
thhem greatly.
Great work! I have a question pertaining to your script;
I have a python script I am running, and I would need to trigger ” ctrl c” through the script instead of manual keyboard input. Suggestions?
Having lots of fun with this.
May try to mix things up with native unix espeak and
surfraw -elvis…. news api’s
Ill let you know if there are any advantages.
Cheers.
Hi, thank you so much for this article. I’m wondering is there any way i can make it run and stop recording automatically without press CTRL+C
you can use the -t
i used -t 00:00:03 that will stop at 3 seconds…
So did you have to modify any ALSA configs to allow use of your webcams mic to record? Or do anything else I may be missing before I run out to buy a different webcam? Add user to audio group? I’m not entirely convinced it’s my mic yet, when I try to practice recording with arecord, I get an error telling me that arecord: main:682: audio open error: no such file or directory, which is leading me to believe that maybe I don’t have something configured right to allow for recording?
not really, I didn’t modify any config, didn’t install any additional package apart from the ones I mentioned in the post. The video and audio on the webcam just works without any effort, it was almost as easy as plug-and-play for the webcam I used.
What kind of Mic have you got there? would there be some sort of driver issue? have you used it previously on a Linux OS computer? I would google the brand and model of your mic to see if how people are using in in Linux OS or rasbian OS.
sorry I am not much of a help, When it comes to hardware issue it’s difficult since it really varies from case to case.
Hi, I log on to your new stuff regularly. Your writing style is witty, keep doing what you’re doing!
thank you! :)
Hello again Oscar, I apologize if I am bombarding your blog. I thought this was worth sharing though
http://www.wolfram.com/raspberry-pi/
Apparently wolfram is now available through the Pi foundations. Very neat!
Not at all Tyler!
That’s very useful. I will update the post and put this link in shortly!
Thank you very much for sharing! :-)
Hello again Oscar, I do believe you are right, that it must be a hardware issue. I do believe that although my Rpi recognizes the webcame, the built in Mic must not be picking up. Could you possibly tell me what model of webcam you are using? I am using a logitech c905. Totally got the facial recognition working today though, after 4 days of trying ;) Thank you again for keeping me busy.
I resolved the issue I was having before about getting the no wolframalpha module by moving the wolfram files into my speech_recognition folder/dir, now however when I try speech2text.sh or main.sh I keep getting an overrun error Recording… Press Ctrl+C to Stop.
overrun!!! (at least 19.241 ms long)
Processing…
cut: invalid byte or field list
Try `cut –help’ for more information.
You Said: Me: ,
Robot: , Sorry, I am not sure.
any suggestions?
You are certainly keeping me busy here, thank you for actually getting me using my pi!
ha! Seems like you have figured out most of your questions yourself.
As for your newest question, have you tried running only the speech to text part alone? making sure the RPi can interpret what you say? From what I see here, it could be software or hardware (your mic)
Dear friends, everything is working piece by piece, except while doing :
wget -U “Mozilla/5.0” –post-file file.flac –header “Content-Type: audio/x-flac; rate=16000” -O – “http://www.google.com/speech-api/v1/recognize?lang=en-us&client=chromium”
giving me error:
HTTP request sent, awaiting response… 500 Internal Server Error
2013-11-16 23:33:05 ERROR 500: Internal Server Error
Such a great post, but i want to intergrate this with some commands for my pi etc.
How to i remove the speech2text part of the main so i can test through my keyboard?
Basically im looking to use “pi {command} {variable}” so “pi google time in london” would use this (so word google runs main.sh) but “pi turn on light” would run seperate scripts.
Purely for testing, i will reinstate it in my finished project. (voice activated night light for a toddler)
To run only the “text to speech” part, you can use the “text2speech.sh”script, with the text appended to it, e.g.:
Good project, hope you have some good result :-)
Hi, thanks for the reply but i can do that bit.
What i was after was queryprocess.py “question” with the text2speech.sh output.
Currently the main.sh run from what is in the .txt file but i was hoping to just string the 2 scripts together ignoring that first section. (once again only for testing so those around me dont think im going mad talking to a computer all day)
Thank you for the turorial, it´s excellent.
However, I have a problem with the answers I get from Wolfram: if an answer has athis character -> | for example “1 | noun | some text” the text2speech script will only read the string infornt of the “|” character (in this case: “1”)
FYI I´m using the simple text2speech script (couldn´t get the other one to work). I´m also using omxplayer instead of mplayer
Thank you Oscar for posting this great idea. It’s exciting as a new programmer to start with a RPi and working with Linux for the first time. However, I do note some issues with the SpeechtoText.sh code. Here is my experience:
a) if you run ‘ffmpeg -loglevel verbose’ and run the bash script, you see the ‘deprecated’ alert and advice to use ‘avconv’ as the new command. So I changed the code there *ffmpeg = avconv as far as I can see – compare help files to see this
b) run ./speechtotext.sh to start recording, but when I ctrl+c to stop, say after 3 seconds of speaking, the flac file fails to be created and no translation to text occurs. I need to record for at least 5 seconds to get a successful flac file. This seems to be a result of the “pipeline” in the bash script to execute ‘arecord’ and immediately ‘ffmpeg’. I fixed this by splitting the pipeline into two distinct commands in the script:
…
arecord… -t wav > speech.wav
avconv…. -i speech.wav …. (explicitly specifying the input file to be converted)
…
Just my small contribution to this blog.
regards
Matt Nassau
Could you please post your entire (modified) script?
I’m having the same 5 second problem you describe, but modifying as you explain does not seem to fix it. In fact, it breaks, only returning “You Said: %”. It must be something stupid simple that I’m missing, but I cannot seem to nail it down.
Thanks in advance.
-Shane
Hi Oscar,
Thank you for an amassing guide. Just a one note, I had to invoke
sudo python setup.py install
instead of just
sudo python setup.py
But everything else worked perfectly :)
Thanks again,
Radek
Please note the comment above about
sudo pythong setup.py install
But other than that, brilliant. Loving it, will add it to my list of tutorials with the Pi, might combine with the PiFm tutorial from another site and Pipe the audio output to an FM frequency!
Hello,
I have been battling with the Speech api for some time now, no matter how I send the file, curl or wget, google never responds…
This is all of my wget output:
–2013-09-16 23:28:26– http://www.google.com/speech-api/v1/recognize?lang=en-us&client=chromium
Resolving http://www.google.com (www.google.com)… 74.125.227.115, 74.125.227.113, 74.125.227.116, …
Connecting to http://www.google.com (www.google.com)|74.125.227.115|:80… connected.
HTTP request sent, awaiting response…
and it just sits there…
Any suggestion?
sounds like you are having a DNS issue, maybe your network, maybe your router…
try to force ipv4 by replacing:
with
let me know if that works for you. :-)
It seems to be the same issue. Maybe it has to do with me using ICS to connect my pi to the internet?
Interestingly enough, I ran a perl version of this process from my laptop, and it worked properly. Thanks for the insight!
Hey,
first: Very good articel and sorry for my bad englisch.
I have a problem by the first step:
I get no respond. At the moment it is the same code. The other examples working fine.MY microfone is working well on the Raspberry Pi too.
I’m reseaching Voice Recognition on Raspberry Pi to control GPIO , example control LED .But in my country hasn’t have document about this issue
what operating system it works on ? Raspbian or Arch Linux
please add my contact
(skype) nguyenlong.0805
(gmail) [email protected]
I want to discuss about issue . thanks
it’s Raspbian.
can u explain the code … speech2text.sh and text2speech.sh
I wanna input of text2speech.sh is the file .txt
I’m newbie :D
Hey Oscar, I have a couple of questions:
1. When I tried sudo apt-get install ffmpeg I got this error:
E: Unable to locate package ffmeg
2. When I tried apt-get install python-setuptools easy_install pip I got this error:
E: Unable to locate package easy_install
E: Unable to locate package pip
3. When I attempt to run ./queryprocess.py and type in “what time is it?” I got this error:
bash: ./queryprocess.py: Permission denied
For my comment above:
How could I fix those errors? Thanks!
have you tried running:
sudo upgrade
sudo update
?
it also depends on what distro you are using… i was using Resbian. you might want to find out the different package name of yours.
I am having the same issue, when I run ./queryprocess.py “what time is it?” it returns permission denied. Did you find a solution for this issue? I have run update and upgrade, I am running current version of raspbian
Very strange error! I have not seen this error myself.
do you only get this error when you ask “what time is it” Question?
I resolved this issue with chmod +x to make it executable, and I initially had the program “running” but kept getting the I don’t know response, now I am getting no module named wolframalpha?
This tutorial is really well-put-together! Thanks for taking the time to make this so readable! I’m having issues however with my text2speech.sh. When I try to run it on a test phrase, i.e. ./text2speech.sh “hello world”, I’m not able to see anything on the command line, nor does mplayer terminate. I took the -really-quiet command out and I get a printout of what is going on (I think…) and it seems that mplayer is reading in my string and is configured for the ffmpeg codec, but I just get a cursor blinking below the command. Any ideas?
Thanks again for such a cool tutorial!
I’m getting the error “overrun!!!” followed by various miliseconds. Not working. Any ideas?
Palle, did you ever find a solution for this?
I am having the same issue.
Hello!
I have changed into polish:
say() { local IFS=+;/usr/bin/mplayer -ao alsa -really-quiet -noconsolecontrols “http://translate.google.com/translate_tts?tl=pl&q=${SHORT[$key]}”; }
But I have troubles with reading polish characters (ą, ę, ś, ć etc.)
It’s mobile site: http://meyerweb.com/eric/tools/dencoder/
String “Literki ą ś ć ń ź” is translated to:
“Literki%20%C4%85%20%C5%9B%20%C4%87%20%C5%84%20%C5%BA”
Unfortunatelly:
root@raspberrypi:/home/pi# /home/pi/scripts/text2speech_pl.sh “Literki%20%C4%85%20%C5%9B%20%C4%87%20%C5%84%20%C5%BA”
Causes only read the “literki”, so that’s not it …
Any ideas?
Hi
I Have problem to use the Wolframalpha Python library.
i downloaded it and unzip it but i have no idea where am i suppose to put it. am i copy it on my bootup flash ?
and another problem i have is, after run the ./speech2text.sh and say something in mic and push control C, takes a lot of time to show my text. like a minut. it’s not fast as video on this page.
thank You
Hi
it doesn’t matter where you put it, you just need to install it and can forget about it.
the speed depends on: 1. how much stuff are running on your Pi, 2. How fast your internet connection is.
Hi
Thank you for your reply. i download:
https://pypi.python.org/pypi/wolframalpha
and unzip it
and run:
apt-get install python-setuptools easy_install pip
but i have this error
E: Could not open lock file /var/lib/dpkg/lock – open (13: Permission denied)
E: Unable to lock the administration directory (/var/lib/dpkg/), are you root?
could you tell me why i have this error ?
and how can i find out any other stuff running on my Rpi?
Thank you
Thank you
You need to run the command as root,
Run sudo apt-get install python-setuptools easy_install pip instead.
Thanks for the tutorial!
Which is the best mic for this purpose? in matter of the mic’s range
Any mic would do. about the mic I am not the best man for this question. try google it.
my RC script make C language…
is sh convert c…?
c -> sh. . .. ?~!!
Hi .. I live in South Korea is the user pie.
Question something.
How to add a command do?
For example.
When I say that rc.
Enter RC Mode pi is to say, after having
/ home / pi / wiringPi / RC ./RCv9 in the path expressions that run the compiled file
And the remote control RC cars try.
you can modify my bash script, to add a if/switch, to check what command you just told the RPi.
and then run your script within the if/switch statement. for example
Might be mistake in the example (not a good bash programmer myself) but that how i would do it.
oh my god I love you.
I think more this problem
Thank you Oscar ♡_♡
# Run your script < < < < This part my script path input?
yes, or do something you want. To run a script you can do this
but you need to make the script ‘executable’ first in command line
chmod +x ascript.sh
oh my god…
my RCv9 < sh?
I got Wolframalpha working thanks
When I try to hear what is said at the text2speech stage I had to add the nolirc=yes line because of the error
In the command line I enter ./text2speech “Hello my name is Ethan”
This runs with no errors but I cannot hear anything even if the tv volume is at the max
I know it is not the tv because i was playing mp3 files with omxplayer earlier when I was connecting up my wiimote
Does anyone know how to correct this so I can hear what is said?
Thanks
I get an error at every stage of this :/
When I try to capture audio it says:
arecord: main:682: audio open error: No such file or directory
ffmpeg version 0.8.6-6:0.8.6-1+rpi1, Copyright (c) 2000-2013 the Libav developers
built on Mar 31 2013 13:58:10 with gcc 4.6.3
*** THIS PROGRAM IS DEPRECATED ***
This program is only provided for compatibility and will be removed in a future release. Please use avconv instead.
pipe:: Invalid data found when processing input
When I tried just to do a wolfram alpha query my python code would not work – i have done mostly perl programming but I could not find an error in the script yet it would not run
Any help is greatly appreciated
Did you find a solution to this error?
Great work !!
It worked for me initially but now my raspberry pi is not converting wav recorded using arecord to flac using either ffmpeg / sox , the converted file sounds like static noise and google tells me no match found. Can you please help ?
thanks, have you checked your mic, maybe try a different mic? if it worked initially, I don’t think it would be related to the software but hardware.
Hi Im verry happy coz find this tuto, my doubt is necessary be connect in the net always?
Thanks
Hi, yes it has to be connected with the internet all the time, because we are using Google’s online speech application.
I get an error at every stage of this :/
When I try to capture audio it says:
arecord: main:682: audio open error: No such file or directory
ffmpeg version 0.8.6-6:0.8.6-1+rpi1, Copyright (c) 2000-2013 the Libav developers
built on Mar 31 2013 13:58:10 with gcc 4.6.3
*** THIS PROGRAM IS DEPRECATED ***
This program is only provided for compatibility and will be removed in a future release. Please use avconv instead.
pipe:: Invalid data found when processing input
When I tried just to do a wolfram alpha query my python code would not work – i have done mostly perl programming but I could not find an error in the script yet it would not run
Any help is greatly appreciated
Hi i get a error like this ‘./speech2text.sh: line 6: stt.txt: Permission denied’.How could i fixed it?
Hi, try create a new text file, and call it “stt.txt”. Then give yourself read and write permission to it. Or simple delete the old “stt.txt” file, the script should create a new one for you with correct permission.
For the unicode error, I’ve had some success using the UnicodeDammit module from BeautifulSoup on strings in general – not perfect, since the library is more designed to work with ML documents, but it can help. Also big fan of unidecode, which is a good catchall solution (does its best to convert accented characters into their unaccented equivalents, which can be nicer than just doing an ascii ignore)
Thanks for the information, I also suspect if this is something to do with system language package because one of my friends claims he didn’t have this error. Mine was straight out of the box, so I didn’t install any language package at all.
When i start the speech2text.sh with the command chmod +x text2speech.sh
it just makes a new line with nothin in:
pi@raspberry …… chmod +x text2speech.sh
pi@raspberry…….
that command is just to change permission on the file (executable). so it’s normal it returns nothing.
to run the script, you need this command:
./text2speech.sh
maybe I should make it more clear in the article.
when i try to install Wolfram Alpha Python Interface
i type apt-get install python-setuptools easy_install pip
and get: E: Unable to locate package easy_install……..
do you have a solution?
1. are you connected to internet?
2. have you run sudo upgrade
3. have you run sudo update
Yes!
After having run both upgrades, I’m running into the same issue. when i use the sudo command i get unable to locate packages, when i dont it tells me it can’t open a lock file /var/lib/dpkg/lock – open (13:permission denied)
Then tells me unable to lock the administration directory (/var/lib/dpkg/) and asks if I’m root
emh… I am curious what OS are you running on the Pi?
You just enter “sudo apt-get install python-setuptools” into the command line then unpackage it and build it
I didnt unpackage and build it but once I typed that line of code into the terminal it worked for me
I too had that error until i did that
Excellent Tutorial!
Very well presented and easy to follow.
I’m very excited to get this to work with my CEC controls to allow me to control my tv with voice :)
awesome work
Thanks Steve! :-)
Glad you find it useful!
Welldone,,good work.
when i was trying this speech to text conversion,i didn’t get the text..
I’ve installed ffmpeg..program also working without any error..but i didn’t get the output..
yes my rpi is connected when i write this command :sudo apt-get install ffmpeg
it’s start and it’s going and in the middle i have a error
Thank you for your great article. actually i was stop in first step, when i was trying to do this:
sudo apt-get install ffmpeg
I have a error like this
unable to connect to raspbian.caro.net:http:
Are you connected to the internet on the Raspberry Pi? Try this command, you should getting response if you are connected.
ping google.com
you could also try running this first for updates:
sudo upgrade
sudo update
Well done, I certainly enjoyed reading this article. I will be trying this out as soon as I find a suitable microphone for my application. Question though, have you tried running the script using python as an active listener, so you wouldn’t have to keep restarting the script?
Thank you.
Not really I was trying to keep this project as short as I can so it’s easy for everyone to pick up and modify it for their own project.
Are you planning to do this? would you mind letting me know if your project is going to be available online?
I modified a few parts of the script to allow for this.
I dont think i am going to put it online, but if I do I will surely credit you.
Why would you not put it online? I could be of great help.
I came here looking to accomplish this exact thing. It is uncanny how similar it is to what I had in mind. Anyways, I’m looking into doing active listening for my first Pi project. My aim is to add a 16×2 lcd display that will print the response from Wolfram Alpha in addition to speaking the response. The one thing I haven’t figured out is the active listening.
@Matt – You found the script online and did something cool with it. It is within the spirit of the community to give back the results. I can respect your decision; I just don’t understand the motivations.